Measurement noise and exact inference
In this notebook, we illustrate how to use pyABC with different noise models. For simplicity, we use a simple ODE model of a conversion reaction.
[ ]:
# install if not done yet
!pip install pyabc --quiet
[1]:
import matplotlib.pyplot as plt
import numpy as np
import scipy as sp
import pyabc
%matplotlib inline
pyabc.settings.set_figure_params('pyabc') # for beautified plots
# initialize global random state
np.random.seed(2)
# initial states
init = np.array([1, 0])
# time points
n_time = 10
measurement_times = np.linspace(0, 10, n_time)
def f(y, t0, theta1, theta2=0.12): # noqa: ARG001
"""ODE right-hand side."""
x1, x2 = y
dx1 = -theta1 * x1 + theta2 * x2
dx2 = theta1 * x1 - theta2 * x2
return dx1, dx2
def model(p: dict):
"""ODE model."""
sol = sp.integrate.odeint(f, init, measurement_times, args=(p['theta1'],))
return {'X_2': sol[:, 1]}
# true parameter
theta_true = {'theta1': 0.08}
# uniform prior distribution
theta1_min, theta1_max = 0.05, 0.12
theta_lims = {'theta1': (theta1_min, theta1_max)}
prior = pyabc.Distribution(
theta1=pyabc.RV('uniform', theta1_min, theta1_max - theta1_min)
)
# true noise-free data
true_trajectory = model(theta_true)
# population size
pop_size = 500
However, we assume that our measurements are subject to additive Gaussian noise:
[2]:
%%time
for _ in range(1):
model(theta_true)
CPU times: user 1.49 ms, sys: 0 ns, total: 1.49 ms
Wall time: 2.07 ms
[3]:
# noise standard deviation
sigma = 0.02
def model_noisy(pars):
"""Add noise to model output"""
sim = model(pars)
return {'X_2': sim['X_2'] + sigma * np.random.randn(n_time)}
# the actual observed data
measured_data = model_noisy(theta_true)
# plot data
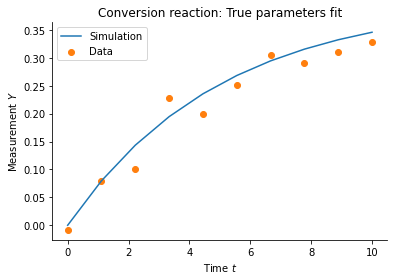
plt.plot(
measurement_times, true_trajectory['X_2'], color='C0', label='Simulation'
)
plt.scatter(measurement_times, measured_data['X_2'], color='C1', label='Data')
plt.xlabel('Time $t$')
plt.ylabel('Measurement $Y$')
plt.title('Conversion reaction: True parameters fit')
plt.legend()
plt.show()
True posterior
For this cute model, we can calculate the actual posterior distribution. The content of this section is not necessary to understand the concept of exact inference and may be skipped.
[4]:
def normal_dty(y_bar, y, sigma):
"""Uncorrelated multivariate Gaussian density `y_bar ~ N(y, sigma)."""
y_bar, y, sigma = y_bar.flatten(), y.flatten(), sigma.flatten()
return np.prod(
1
/ np.sqrt(2 * np.pi * sigma**2)
* np.exp(-(((y_bar - y) / sigma) ** 2) / 2)
)
def posterior_unscaled_1d(p):
"""Unscaled posterior density."""
# simulations and sigmas as arrays
y = model(p)['X_2'].flatten()
sigmas = sigma * np.ones(n_time)
# unscaled likelihood
likelihood_val = normal_dty(measured_data['X_2'], y, sigmas)
# prior
prior_val = prior.pdf(p)
return likelihood_val * prior_val
# the integral needs to be 1
posterior_normalization = sp.integrate.quad(
lambda x: posterior_unscaled_1d({'theta1': x}), *theta_lims['theta1']
)[0]
def posterior_scaled_1d(p):
"""Posterior over theta with integral 1."""
return posterior_unscaled_1d(p) / posterior_normalization
# calculate posterior on grid values
xs = np.linspace(*theta_lims['theta1'], 200)
true_fvals = [posterior_scaled_1d({'theta1': x}) for x in xs]
Ignoring noise
In the notebook “Ordinary Differential Equations: Conversion Reaction”, this model is used without accounting for a noise model, which is strictly speaking not correct. In this case, we get the following result:
[5]:
def distance(simulation, data):
"""Here we use an l2 distance."""
return np.sum((data['X_2'] - simulation['X_2']) ** 2)
abc = pyabc.ABCSMC(model, prior, distance, population_size=pop_size)
abc.new(pyabc.create_sqlite_db_id(), measured_data)
history_ignore = abc.run(max_nr_populations=7)
INFO:Sampler:Parallelizing the sampling on 4 cores.
INFO:History:Start <ABCSMC id=1, start_time=2021-02-21 20:27:26.286121>
INFO:ABC:Calibration sample t=-1.
INFO:Epsilon:initial epsilon is 0.023105087979925738
INFO:ABC:t: 0, eps: 0.023105087979925738.
INFO:ABC:Acceptance rate: 500 / 1005 = 4.9751e-01, ESS=5.0000e+02.
INFO:ABC:t: 1, eps: 0.008745577704180732.
INFO:ABC:Acceptance rate: 500 / 1004 = 4.9801e-01, ESS=4.9539e+02.
INFO:ABC:t: 2, eps: 0.005699516985076191.
INFO:ABC:Acceptance rate: 500 / 994 = 5.0302e-01, ESS=4.9133e+02.
INFO:ABC:t: 3, eps: 0.004817194659694434.
INFO:ABC:Acceptance rate: 500 / 955 = 5.2356e-01, ESS=4.9845e+02.
INFO:ABC:t: 4, eps: 0.0045352066148319665.
INFO:ABC:Acceptance rate: 500 / 1016 = 4.9213e-01, ESS=4.9959e+02.
INFO:ABC:t: 5, eps: 0.004481251520102031.
INFO:ABC:Acceptance rate: 500 / 954 = 5.2411e-01, ESS=4.9735e+02.
INFO:ABC:t: 6, eps: 0.00446711405590255.
INFO:ABC:Acceptance rate: 500 / 979 = 5.1073e-01, ESS=4.9718e+02.
INFO:pyabc.util:Stopping: maximum number of generations.
INFO:History:Done <ABCSMC id=1, duration=0:00:12.091309, end_time=2021-02-21 20:27:38.377430>
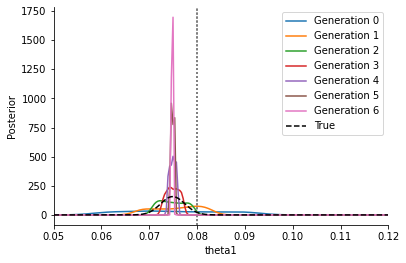
As one can see in the below plot, this converges to a point estimate as \(\varepsilon\rightarrow \varepsilon_\text{min}>0\), and does not correctly represent the posterior. In particular, in general this point estimate will not capture the correct parameter value (indicated by the grey line). Furthermore, its exact location will depend on the distance function – using an l1 instead of the here used l2 distance will result in a different peak (namely the MLE of an assumed Laplace noise model).
[6]:
_, ax = plt.subplots()
for t in range(history_ignore.max_t + 1):
pyabc.visualization.plot_kde_1d_highlevel(
history_ignore,
x='theta1',
t=t,
refval=theta_true,
refval_color='grey',
xmin=theta1_min,
xmax=theta1_max,
numx=200,
ax=ax,
label=f'Generation {t}',
)
ax.plot(xs, true_fvals, color='black', linestyle='--', label='True')
ax.legend()
plt.show()
Add noise to the model output
To correctly account for noise, there are essentially two possibilities: Firstly, we can use the noisified model output:
[7]:
abc = pyabc.ABCSMC(model_noisy, prior, distance, population_size=pop_size)
abc.new(pyabc.create_sqlite_db_id(), measured_data)
history_noisy_output = abc.run(max_nr_populations=8)
INFO:Sampler:Parallelizing the sampling on 4 cores.
INFO:History:Start <ABCSMC id=2, start_time=2021-02-21 20:27:39.095035>
INFO:ABC:Calibration sample t=-1.
INFO:Epsilon:initial epsilon is 0.026838722815439364
INFO:ABC:t: 0, eps: 0.026838722815439364.
INFO:ABC:Acceptance rate: 500 / 978 = 5.1125e-01, ESS=5.0000e+02.
INFO:ABC:t: 1, eps: 0.013429737366067502.
INFO:ABC:Acceptance rate: 500 / 1024 = 4.8828e-01, ESS=4.9818e+02.
INFO:ABC:t: 2, eps: 0.009244439942835643.
INFO:ABC:Acceptance rate: 500 / 1294 = 3.8640e-01, ESS=4.4998e+02.
INFO:ABC:t: 3, eps: 0.007235887322983637.
INFO:ABC:Acceptance rate: 500 / 2034 = 2.4582e-01, ESS=4.4500e+02.
INFO:ABC:t: 4, eps: 0.005884828057762174.
INFO:ABC:Acceptance rate: 500 / 3244 = 1.5413e-01, ESS=4.0955e+02.
INFO:ABC:t: 5, eps: 0.004769564880814353.
INFO:ABC:Acceptance rate: 500 / 6646 = 7.5233e-02, ESS=3.7692e+02.
INFO:ABC:t: 6, eps: 0.00400354214154976.
INFO:ABC:Acceptance rate: 500 / 13123 = 3.8101e-02, ESS=4.1908e+02.
INFO:ABC:t: 7, eps: 0.003439505458551804.
INFO:ABC:Acceptance rate: 500 / 23288 = 2.1470e-02, ESS=4.3150e+02.
INFO:pyabc.util:Stopping: maximum number of generations.
INFO:History:Done <ABCSMC id=2, duration=0:00:58.700816, end_time=2021-02-21 20:28:37.795851>
[8]:
_, ax = plt.subplots()
for t in range(history_noisy_output.max_t + 1):
pyabc.visualization.plot_kde_1d_highlevel(
history_noisy_output,
x='theta1',
t=t,
refval=theta_true,
refval_color='grey',
xmin=theta1_min,
xmax=theta1_max,
ax=ax,
numx=200,
label=f'Generation {t}',
)
ax.plot(xs, true_fvals, color='black', linestyle='--', label='True')
ax.legend()
[8]:
<matplotlib.legend.Legend at 0x7faf45da9460>
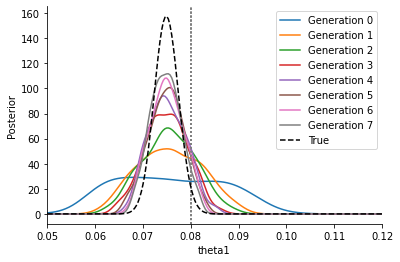
This curve is much broader and closer to the correct posterior, approaching it gradually. The epsilon thresholds converge to zero \(\varepsilon\rightarrow 0\), however for \(\varepsilon>0\) there remains a slight overestimation of the uncertainty which only gradually fades when decreasing \(\varepsilon\) further.
Modify the acceptance step
Secondly, we can alternatively use the non-noisy model, but adjust the acceptance step:
[9]:
acceptor = pyabc.StochasticAcceptor()
kernel = pyabc.IndependentNormalKernel(var=sigma**2)
eps = pyabc.Temperature()
abc = pyabc.ABCSMC(
model, prior, kernel, eps=eps, acceptor=acceptor, population_size=pop_size
)
abc.new(pyabc.create_sqlite_db_id(), measured_data)
history_acceptor = abc.run(max_nr_populations=10)
INFO:Sampler:Parallelizing the sampling on 4 cores.
INFO:History:Start <ABCSMC id=3, start_time=2021-02-21 20:28:39.288933>
INFO:ABC:Calibration sample t=-1.
INFO:ABC:t: 0, eps: 10.619660838142671.
INFO:ABC:Acceptance rate: 500 / 1682 = 2.9727e-01, ESS=5.0000e+02.
INFO:ABC:t: 1, eps: 1.3435421981618625.
INFO:ABC:Acceptance rate: 500 / 1580 = 3.1646e-01, ESS=4.9719e+02.
INFO:ABC:t: 2, eps: 1.0.
INFO:ABC:Acceptance rate: 500 / 830 = 6.0241e-01, ESS=3.3374e+02.
INFO:pyabc.util:Stopping: minimum epsilon.
INFO:History:Done <ABCSMC id=3, duration=0:00:11.852764, end_time=2021-02-21 20:28:51.141697>
We use a pyabc.StochasticAcceptor for the acceptor, replacing the default pyabc.UniformAcceptor, in order to accept when
where \(\pi(D|y,\theta)\) denotes the distribution of noisy data \(D\) given non-noisy model output \(y\) and parameters \(\theta\). Here, we use a pyabc.IndependentNormalKernel in place of a pyabc.Distance to capture the normal noise \(\pi(D|y,\theta)\sim\mathcal{N}(D|y,\theta,\sigma)\). Also other noise models are possible, including Laplace or binomial noise. In place of the pyabc.Epsilon, we employ a pyabc.Temperature which implements schemes to decrease a
temperature \(T\searrow 1\), s.t. in iteration \(t\) we sample from
where \(p(y|\theta)\) denotes the model output likelihood, and \(\pi(\theta)\) the parameters prior.
Each of acceptor, kernel and temperature offers various configuration options, however the default parameters have shown to be quite stable already.
[10]:
_, ax = plt.subplots()
for t in range(history_acceptor.max_t + 1):
pyabc.visualization.plot_kde_1d_highlevel(
history_acceptor,
x='theta1',
t=t,
refval=theta_true,
refval_color='grey',
xmin=theta1_min,
xmax=theta1_max,
ax=ax,
numx=200,
label=f'Generation {t}',
)
ax.plot(xs, true_fvals, color='black', linestyle='--', label='True')
ax.legend()
plt.show()
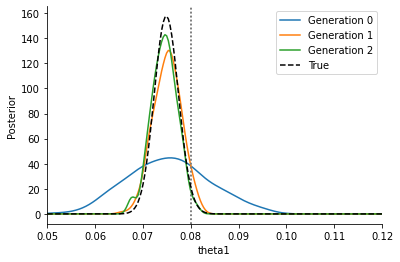
We see that we get a similar posterior distribution as with the noisy output. It matches the true posterior better actually, indicating that already for this simple problem, standard ABC has a hard time reproducing the posterior. Moreover, the posterior is obtained at a much lower computational cost, as the below plot shows:
[11]:
histories = [history_noisy_output, history_acceptor]
labels = ['noisy model', 'stochastic acceptor']
pyabc.visualization.plot_sample_numbers(histories, labels)
plt.show()
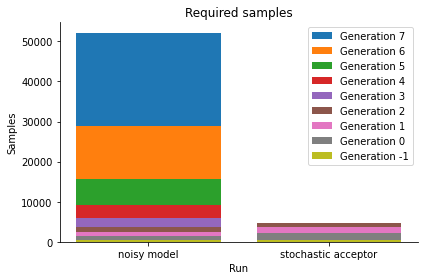
Thus, the stochastic acceptor is the method of choice for exact inference. Note that for practical applications it requires in general more simulations than inference without a, or effectively thus with a uniform, noise model. For further details please consult the API documentation and the mentioned manuscript.
Estimate noise parameters
Our formulation of the modified acceptance step allows the noise model to be parameter-dependent (so does in theory also the noisified model output). Thus one can estimate parameters like e.g. the standard deviation of Gaussian noise on-the-fly.
Parameters are often estimated on a logarithmic scale if fold changes are of interest. We show this here exemplarily with the example of the standard deviation of a normal noise kernel:
[12]:
theta_true_var = {'theta1': theta_true['theta1'], 'std': np.log10(sigma)}
std_min, std_max = np.log10([0.002, 1])
theta_lims_var = {
'theta1': (theta1_min, theta1_max),
'std': (std_min, std_max),
}
prior = pyabc.Distribution(
theta1=pyabc.RV('uniform', theta1_min, theta1_max - theta1_min),
std=pyabc.RV('uniform', std_min, std_max - std_min),
)
Also in this scenario, we can calculate for comparison the true posterior:
[13]:
%%time
def posterior_unscaled(p):
"""Unscaled posterior with parameter-dependent noise levels."""
# simulations and sigmas as arrays
y = model(p)['X_2']
sigma = 10 ** p['std'] * np.ones(n_time)
# unscaled likelihood
likelihood_val = normal_dty(measured_data['X_2'], y, sigma)
# prior
prior_val = prior.pdf(p)
return likelihood_val * prior_val
# calculate posterior normalization
posterior_normalization = None
# comment out this line to recompute the normalization
posterior_normalization = 382843631.1961108
if posterior_normalization is None:
posterior_normalization = sp.integrate.dblquad(
lambda std, theta1: posterior_unscaled({'theta1': theta1, 'std': std}),
*theta_lims_var['theta1'],
lambda _: std_min,
lambda _: std_max,
epsabs=1e-4,
)[0]
print(posterior_normalization)
def posterior_scaled(p):
"""Normalized posterior."""
return posterior_unscaled(p) / posterior_normalization
CPU times: user 8 µs, sys: 1 µs, total: 9 µs
Wall time: 20.5 µs
We are interested in the marginal densities w.r.t. theta1 and std:
[14]:
%%time
def marg_theta1(theta1):
"""Posterior marginal w.r.t. theta1."""
return sp.integrate.quad(
lambda std: posterior_scaled({'theta1': theta1, 'std': std}),
*theta_lims_var['std'],
)[0]
def marg_std(std):
"""Posterior marginal w.r.t. std."""
return sp.integrate.quad(
lambda theta1: posterior_scaled({'theta1': theta1, 'std': std}),
*theta_lims_var['theta1'],
)[0]
# calculate the densities on a grid
theta1s = np.linspace(*theta_lims_var['theta1'], 100)
vals_theta1 = [marg_theta1(theta1) for theta1 in theta1s]
stds = np.linspace(*theta_lims_var['std'], 100)
vals_std = [marg_std(std) for std in stds]
CPU times: user 20.8 s, sys: 98.6 ms, total: 20.9 s
Wall time: 25.2 s
The actual implementation of exact inference with estimated variance is as follows:
The arameter-dependent noise model is specified by passing a function to the kernel, which takes the parameters and returns an array of variances corresponding to the data. This is currently implemented for the pyabc.IndependentNormalKernel, pyabc.IndependentLaplaceKernel, pyabc.BinomialKernel.
[15]:
def var(p):
"""Parameterized variance function. Note `var = std**2`."""
return 10 ** (2 * p['std']) * np.ones(n_time)
acceptor = pyabc.StochasticAcceptor()
# pass variance function to kernel
kernel = pyabc.IndependentNormalKernel(var=var)
eps = pyabc.Temperature()
abc = pyabc.ABCSMC(
model, prior, kernel, eps=eps, acceptor=acceptor, population_size=pop_size
)
abc.new(pyabc.create_sqlite_db_id(), measured_data)
history_acceptor_var = abc.run(max_nr_populations=6)
INFO:Sampler:Parallelizing the sampling on 4 cores.
INFO:History:Start <ABCSMC id=4, start_time=2021-02-21 20:29:17.858822>
INFO:ABC:Calibration sample t=-1.
INFO:ABC:t: 0, eps: 18.523365087802798.
INFO:ABC:Acceptance rate: 500 / 1705 = 2.9326e-01, ESS=5.0000e+02.
INFO:ABC:t: 1, eps: 8.75167535084106.
INFO:ABC:Acceptance rate: 500 / 1611 = 3.1037e-01, ESS=4.2604e+02.
INFO:ABC:t: 2, eps: 5.088249506343676.
INFO:ABC:Acceptance rate: 500 / 1824 = 2.7412e-01, ESS=3.7931e+02.
INFO:ABC:t: 3, eps: 2.958323063974092.
INFO:ABC:Acceptance rate: 500 / 2071 = 2.4143e-01, ESS=4.0018e+02.
INFO:ABC:t: 4, eps: 1.719977634730781.
INFO:ABC:Acceptance rate: 500 / 1841 = 2.7159e-01, ESS=3.7095e+02.
INFO:ABC:t: 5, eps: 1.0.
INFO:ABC:Acceptance rate: 500 / 1908 = 2.6205e-01, ESS=3.8768e+02.
INFO:pyabc.util:Stopping: maximum number of generations.
INFO:History:Done <ABCSMC id=4, duration=0:00:27.731354, end_time=2021-02-21 20:29:45.590176>
[16]:
fig, ax = plt.subplots(1, 2)
for t in range(history_acceptor_var.max_t + 1):
pyabc.visualization.plot_kde_1d_highlevel(
history_acceptor_var,
x='theta1',
t=t,
refval=theta_true_var,
refval_color='grey',
xmin=theta1_min,
xmax=theta1_max,
ax=ax[0],
numx=200,
label=f'Generation {t}',
)
pyabc.visualization.plot_kde_1d_highlevel(
history_acceptor_var,
x='std',
t=t,
refval=theta_true_var,
refval_color='grey',
xmin=std_min,
xmax=std_max,
ax=ax[1],
numx=200,
label=f'Generation {t}',
)
ax[1].set_xlabel('log10(std)')
ax[1].set_ylabel(None)
ax[0].plot(theta1s, vals_theta1, color='black', linestyle='--', label='True')
ax[1].plot(stds, vals_std, color='black', linestyle='--', label='True')
ax[1].legend()
fig.set_size_inches((8, 4))
fig.tight_layout()
plt.show()
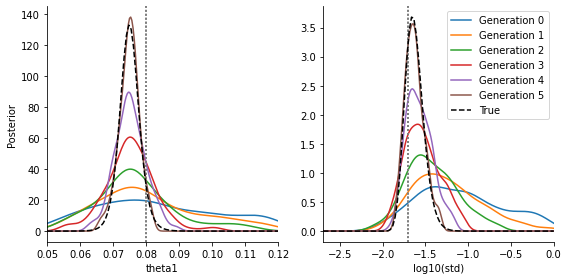
We see that we are able to estimate both parameters quite reasonably (the exact details of course depending on the data and model), they fit to the true posteriors. We omit the comparison in the standard approach with parameter-dependent noise added to the model output, as this performs inferior. It can be trivially implemented.
Fur further aspects, see also this notebook of the underlying study.