Stochastic differential equation: Ion channel noise in Hodgkin-Huxley neurons
Download this notebook here: Stochastic Differential Equation: Ion channel noise in Hodgkin-Huxley neurons
In the following, we estimate parameters of the stochastic differential equation model of ion channel noise in Hodgkin-Huxley neurons presented in:
Goldwyn, Joshua H., Nikita S. Imennov, Michael Famulare, and Eric Shea-Brown. “Stochastic Differential Equation Models for Ion Channel Noise in Hodgkin-Huxley Neurons.” Physical Review E 83, no. 4 (2011): 041908. doi:10.1103/PhysRevE.83.041908.
The code was implemented in Fortran 95 and made available in ModelDB: ModelDB.
(The code is not included in pyABC and neither developed nor maintained by the pyABC developers.)
Download and compilation of the Fortran model
We start by downloading the code from ModelDB. For this, the requests package is needed.
[ ]:
# install if not done yet
!pip install pyabc --quiet
[1]:
import pyabc
pyabc.settings.set_figure_params('pyabc') # for beautified plots
[2]:
import requests
URL = (
'https://senselab.med.yale.edu/modeldb/'
'eavBinDown.cshtml?o=128502&a=23&mime=application/zip'
)
req = requests.request('GET', URL)
The zip file to which URL points is stored in memory. The code is then extracted into a temporary directory and compiled using make HH_run provided as part of the download from ModelDB. The Fortran compiler gfortran is required for compilation.
[3]:
import os
import subprocess
import tempfile
from io import BytesIO
from zipfile import ZipFile
tempdir = tempfile.mkdtemp()
archive = ZipFile(BytesIO(req.content))
archive.extractall(tempdir)
ret = subprocess.run(
['make', 'HH_run'], cwd=os.path.join(tempdir, 'ModelDBFolder')
)
EXEC = os.path.join(tempdir, 'ModelDBFolder', 'HH_run')
print(f'The executable location is {EXEC}')
The executable location is /tmp/tmpg_1jxvip/ModelDBFolder/HH_run
The variable EXEC points to the executable.
A simulate function is defined which uses the subprocess.run function to execute the external binary. The external binary writes to stdout. The output is captured and stored in a pandas dataframe. This dataframe is returned by the simulate function.
[4]:
import numpy as np
import pandas as pd
def simulate(
model=2,
membrane_dim=10,
time_steps=1e4,
time_step_size=0.01,
isi=100,
dc=20,
noise=0,
sine_amplitude=0,
sine_frequency=0,
voltage_clamp=0,
data_to_print=1,
rng_seed=None,
):
"""
Simulate the SDE Ion Channel Model defined
in an external Fortran simulator.
Returns: pandas.DataFrame
Index: t, Time
Columns: V, Na, K
V: Voltage
Na, K: Proportion of open channels
"""
if rng_seed is None:
rng_seed = np.random.randint(2**32 - 2) + 1
membrane_area = membrane_dim**2
re = subprocess.run(
[
EXEC,
str(model),
# the binary cannot very long floats
f'{membrane_area:.5f}',
str(time_steps),
str(time_step_size),
str(isi),
f'{dc:.5f}',
str(noise),
str(sine_amplitude),
str(sine_frequency),
str(voltage_clamp),
str(data_to_print),
str(rng_seed),
],
stdout=subprocess.PIPE,
)
df = pd.read_table(
BytesIO(re.stdout),
delim_whitespace=True,
header=None,
index_col=0,
names=['t', 'V', 'Na', 'K'],
)
return df
Generating the observed data
We run a simulations and plot the fraction of open “K” channels and open “Na” channels:
[5]:
import matplotlib.pyplot as plt
%matplotlib inline
gt = {'dc': 20, 'membrane_dim': 10}
fig, axes = plt.subplots(nrows=2, sharex=True)
fig.set_size_inches((12, 8))
for _ in range(10):
observation = simulate(**gt)
observation.plot(y='K', color='C1', ax=axes[0])
observation.plot(y='Na', color='C0', ax=axes[1])
for ax in axes:
ax.legend().set_visible(False)
axes[0].set_title('K')
axes[0].set_ylabel('K')
axes[1].set_title('Na')
axes[1].set_ylabel('Na');
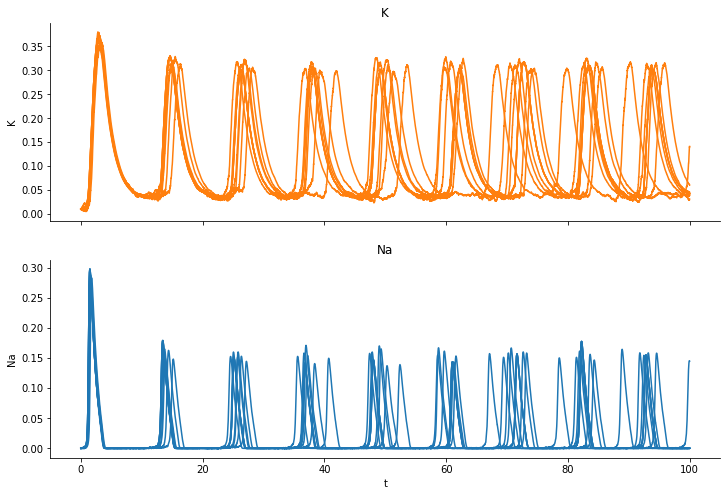
We observe how the channels open and close and also that the individual trajectores differ from realization to realization, even though we simulate for the exact same parameter set. We take the last simulation as observed data.
Defining distance and prior
We’ll now demonstrate how to use pyABC to estimate parameters of the model. Here, we’ll focus on the dc and the membrane_dim parameters. The dc parameter describes the input current, the membrane_dim is the square root of the membrane area. We choose uniform priors:
[6]:
from pyabc import ABCSMC, RV, Distribution
dcmin, dcmax = 2, 30
memmin, memmax = 1, 12
prior = Distribution(
dc=RV('uniform', dcmin, dcmax - dcmin),
membrane_dim=RV('uniform', memmin, memmax - memmin),
)
The distance function is defined as \(L_2\) norm between the fractions of open “K” channels.
[7]:
def distance(x, y):
diff = x['data']['K'] - y['data']['K']
dist = np.sqrt(np.sum(diff**2))
return dist
We also define a small simulate_pyabc wrapper function, which wraps the simulate function. This is needed to comply with the interface expected by pyABC.
[8]:
def simulate_pyabc(parameter):
res = simulate(**parameter)
return {'data': res}
Performing parameter inference with pyABC
We are now ready to start pyABC. As usually, we first initialize the ABCSMC object, then pass the observed data and the database location in which to store the logged parameters and summary statistics, and finally run the inference until the maximum number of allowed populations max_nr_populations or the final acceptance threshold minimum_epsilon is reached.
[9]:
abc = ABCSMC(simulate_pyabc, prior, distance, population_size=100)
abc_id = abc.new(
'sqlite:///' + os.path.join(tempdir, 'test.db'), {'data': observation}
)
history = abc.run(max_nr_populations=10, minimum_epsilon=6)
INFO:Sampler:Parallelizing the sampling on 4 cores.
INFO:History:Start <ABCSMC(id=1, start_time=2021-02-03 13:45:23.566982)>
INFO:ABC:Calibration sample before t=0.
INFO:Epsilon:initial epsilon is 12.027328847344789
INFO:ABC:t: 0, eps: 12.027328847344789.
INFO:ABC:Acceptance rate: 100 / 231 = 4.3290e-01, ESS=1.0000e+02.
INFO:ABC:t: 1, eps: 10.888335491302861.
INFO:ABC:Acceptance rate: 100 / 312 = 3.2051e-01, ESS=8.4622e+01.
INFO:ABC:t: 2, eps: 9.452200516810388.
INFO:ABC:Acceptance rate: 100 / 339 = 2.9499e-01, ESS=9.2592e+01.
INFO:ABC:t: 3, eps: 7.3233850786061705.
INFO:ABC:Acceptance rate: 100 / 347 = 2.8818e-01, ESS=1.9828e+01.
INFO:ABC:t: 4, eps: 6.0421228761347425.
INFO:ABC:Acceptance rate: 100 / 866 = 1.1547e-01, ESS=9.5620e+01.
INFO:ABC:t: 5, eps: 5.5667319007160545.
INFO:ABC:Acceptance rate: 100 / 472 = 2.1186e-01, ESS=9.1021e+01.
INFO:pyabc.util:Stopping: minimum epsilon.
INFO:History:Done <ABCSMC(id=1, duration=0:09:19.027344, end_time=2021-02-03 13:54:42.594326>
Visualization of the estimated parameters
We plot the posterior distribution after a few generations together with the parameters generating the observed data (the dotted line and the orange dot).
[10]:
from pyabc.visualization import plot_kde_matrix
dfw = history.get_distribution(m=0)
plot_kde_matrix(
*dfw,
limits={'dc': (dcmin, dcmax), 'membrane_dim': (memmin, memmax)},
refval=gt,
refval_color='k',
)
[10]:
array([[<AxesSubplot:ylabel='dc'>, <AxesSubplot:>],
[<AxesSubplot:xlabel='dc', ylabel='membrane_dim'>,
<AxesSubplot:xlabel='membrane_dim'>]], dtype=object)
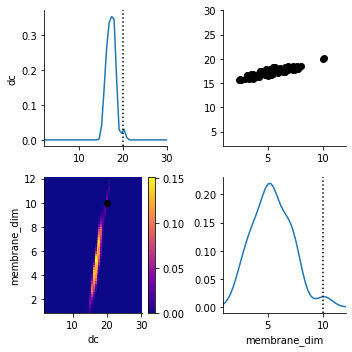
The dc parameter is very well detected. (Don’t get confused by the y-axis. It applies to the scatterplot, not to the marginal distribution.) The distribution of membrane_dim is broader. (Note that even the exact posterior is not necessarily peaked at the ground truth parameters).
Evaluation of the fit
We compare four types of data:
samples from the prior distribution,
samples from the posterior distribution,
the data generated by the accepted parameters, and
the observation.
[11]:
from pyabc.transition import MultivariateNormalTransition
fig, axes = plt.subplots(nrows=3, sharex=True)
fig.set_size_inches(8, 12)
n = 5 # Number of samples to plot from each category
# Plot samples from the prior
alpha = 0.5
for _ in range(n):
prior_sample = simulate(**prior.rvs())
prior_sample.plot(y='K', ax=axes[0], color='C1', alpha=alpha)
# Fit a posterior KDE and plot samples form it
posterior = MultivariateNormalTransition()
posterior.fit(*history.get_distribution(m=0))
for _ in range(n):
posterior_sample = simulate(**posterior.rvs())
posterior_sample.plot(y='K', ax=axes[1], color='C0', alpha=alpha)
# Plot the stored summary statistics
sum_stats = history.get_weighted_sum_stats_for_model(m=0, t=history.max_t)
for stored in sum_stats[1][:n]:
stored['data'].plot(y='K', ax=axes[2], color='C2', alpha=alpha)
# Plot the observation
for ax in axes:
observation.plot(y='K', ax=ax, color='k', linewidth=1.5)
ax.legend().set_visible(False)
ax.set_ylabel('K')
# Add a legend with pseudo artists to first plot
axes[0].legend(
[
plt.plot([0], color='C1')[0],
plt.plot([0], color='C0')[0],
plt.plot([0], color='C2')[0],
plt.plot([0], color='k')[0],
],
['Prior', 'Posterior', 'Stored, accepted', 'Observation'],
bbox_to_anchor=(0.5, 1),
loc='lower center',
ncol=4,
);
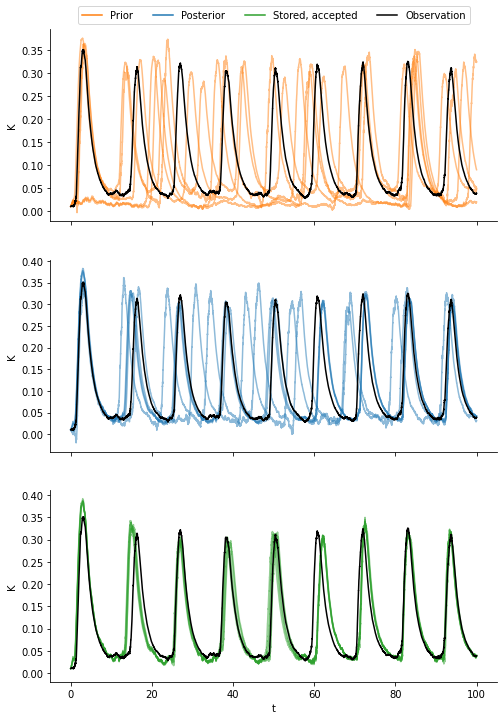
We observe that the samples from the prior exhibit the largest variation and do not resemble the observation well. The samples from the posterior are much closer to the observed data. Even a little bit closer are the samples generated by the accepted parameters. This has at least two reasons: First, the posterior KDE-fit smoothes the particle populations. Second, the sample generated by a parameter that was accepted is biased towards being more similar to the observed data as compared to a random sample from that parameter.